1,116 Downloads Updated 5 months ago
An open-weight language model designed specifically for coding agents and local development
ollama run nishtahir/qwen3-coder-next
Details
Updated 5 months ago
5 months ago
44d603d10cc7 · 50GB ·
Readme
Qwen3-Coder-Next (Unofficial)
Highlights
Qwen3-Coder-Next, an open-weight language model designed specifically for coding agents and local development. It features the following key enhancements:
- Super Efficient with Significant Performance: With only 3B activated parameters (80B total parameters), it achieves performance comparable to models with 10–20x more active parameters, making it highly cost-effective for agent deployment.
- Advanced Agentic Capabilities: Through an elaborate training recipe, it excels at long-horizon reasoning, complex tool usage, and recovery from execution failures, ensuring robust performance in dynamic coding tasks.
- Versatile Integration with Real-World IDE: Its 256k context length, combined with adaptability to various scaffold templates, enables seamless integration with different CLI/IDE platforms (e.g., Claude Code, Qwen Code, Qoder, Kilo, Trae, Cline, etc.), supporting diverse development environments.
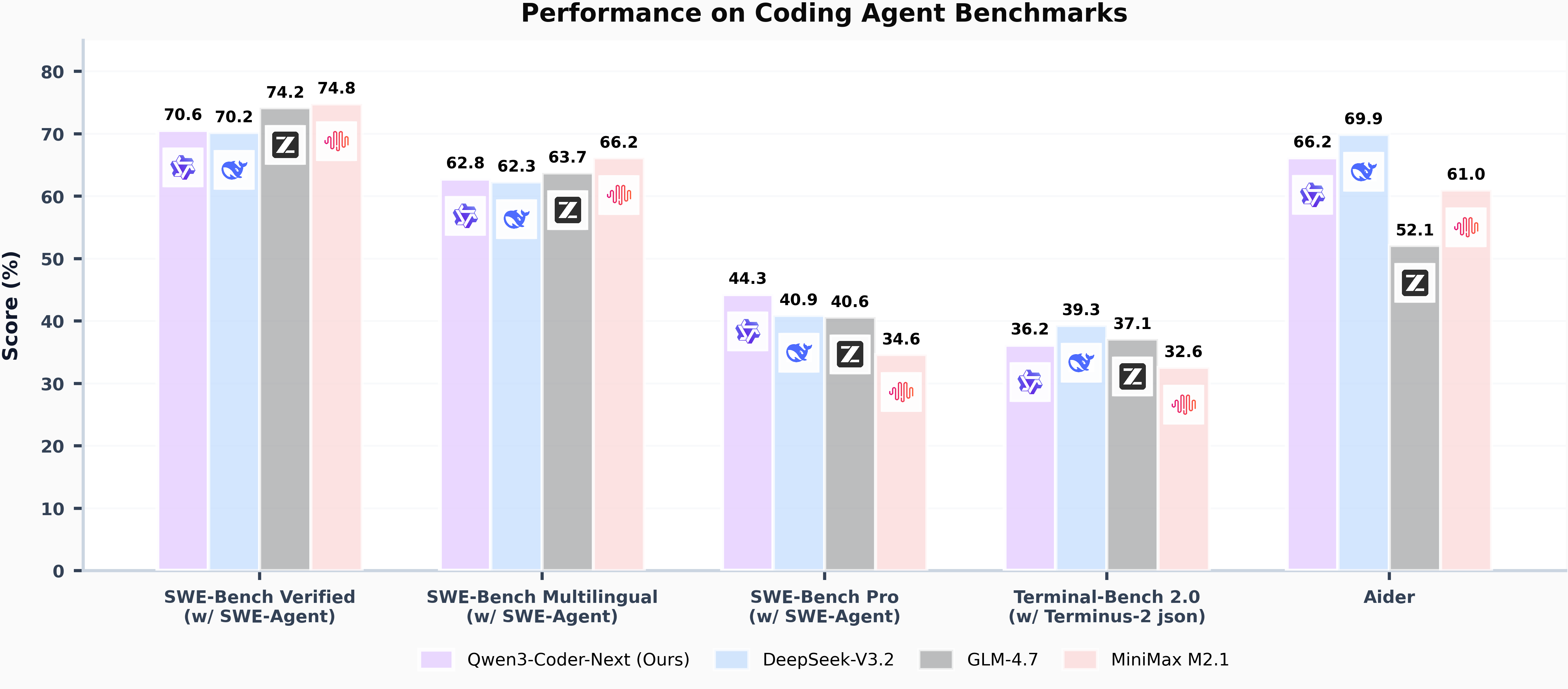
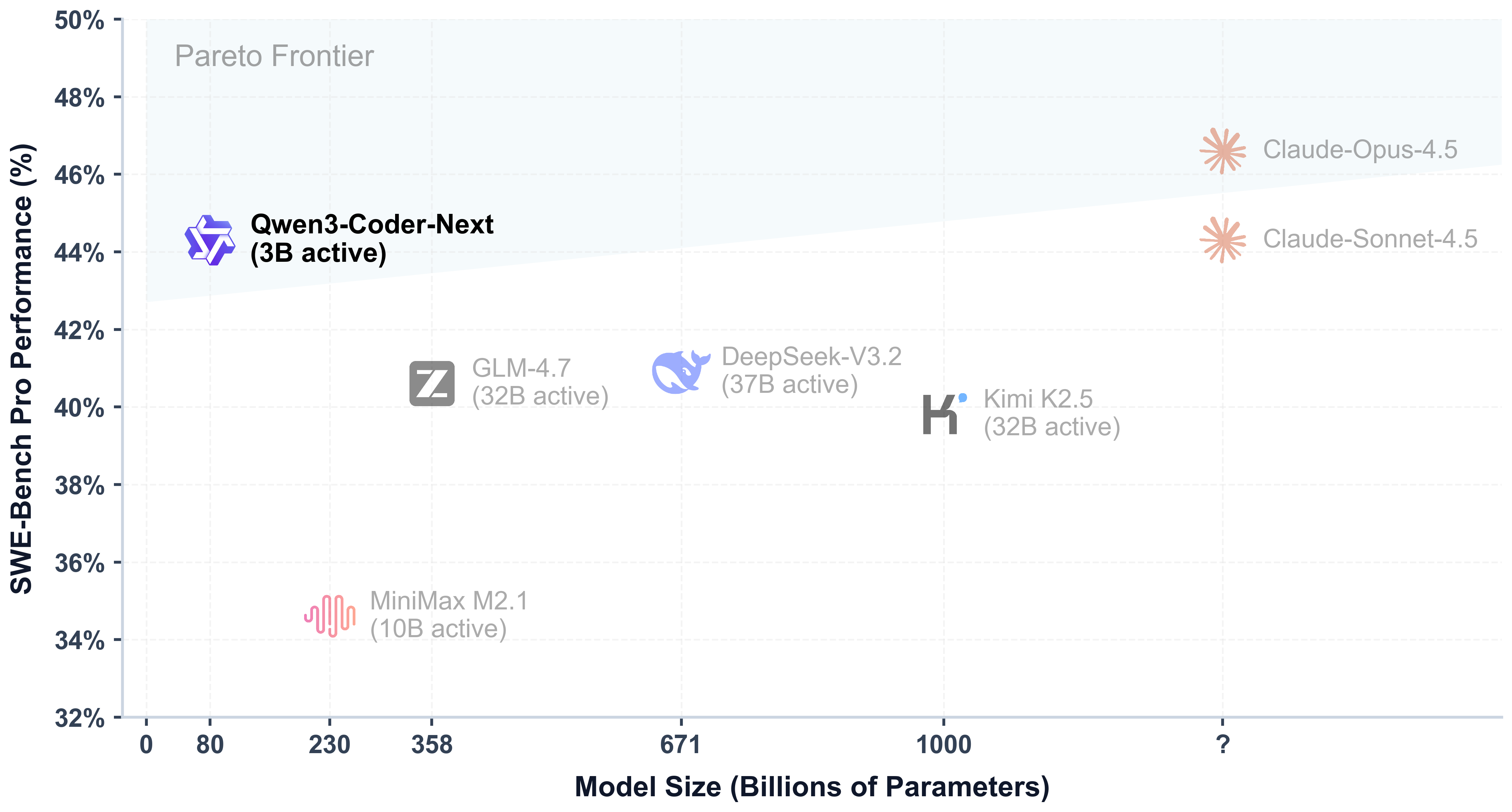
Model Overview
Qwen3-Coder-Next has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 80B in total and 3B activated
- Number of Parameters (Non-Embedding): 79B
- Hidden Dimension: 2048
- Number of Layers: 48
- Hybrid Layout: 12 * (3 * (Gated DeltaNet -> MoE) -> 1 * (Gated Attention -> MoE))
- Gated Attention:
- Number of Attention Heads: 16 for Q and 2 for KV
- Head Dimension: 256
- Rotary Position Embedding Dimension: 64
- Gated DeltaNet:
- Number of Linear Attention Heads: 32 for V and 16 for QK
- Head Dimension: 128
- Mixture of Experts:
- Number of Experts: 512
- Number of Activated Experts: 10
- Number of Shared Experts: 1
- Expert Intermediate Dimension: 512
- Context Length: 262,144 natively
NOTE: This model supports only non-thinking mode and does not generate <think></think> blocks in its output. Meanwhile, specifying enable_thinking=False is no longer required.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our blog, GitHub, and Documentation.