44.9K Downloads Updated 2 years ago
Text embedding model (base) for input of size up to 8192 tokens
ollama pull jina/jina-embeddings-v2-base-en
Models
View all →Readme

The text embedding set trained by Jina AI.
Quick Start
The easiest way to starting using jina-embeddings-v2-base-en is to use Jina AI’s Embedding API.
Intended Usage & Model Info
jina-embeddings-v2-base-en is an English, monolingual embedding model supporting 8192 sequence length.
It is based on a BERT architecture (JinaBERT) that supports the symmetric bidirectional variant of ALiBi to allow longer sequence length.
The backbone jina-bert-v2-base-en is pretrained on the C4 dataset.
The model is further trained on Jina AI’s collection of more than 400 millions of sentence pairs and hard negatives.
These pairs were obtained from various domains and were carefully selected through a thorough cleaning process.
The embedding model was trained using 512 sequence length, but extrapolates to 8k sequence length (or even longer) thanks to ALiBi. This makes our model useful for a range of use cases, especially when processing long documents is needed, including long document retrieval, semantic textual similarity, text reranking, recommendation, RAG and LLM-based generative search, etc.
With a standard size of 137 million parameters, the model enables fast inference while delivering better performance than our small model. It is recommended to use a single GPU for inference.
In ollama hub we provide the following set of models:
jina-embeddings-v2-small-en: 33 million parametersjina-embeddings-v2-base-en: 137 million parameters (you are here).jina-embeddings-v2-base-de: German-English Bilingual embeddings.jina-embeddings-v2-base-es: Spanish-English Bilingual embeddings.
Ollama Usage
This model is an embedding model, meaning it can only be used to generate embeddings.
You can get it by doing ollama pull jina/jina-embeddings-v2-base-en
REST API
curl http://localhost:11434/api/embeddings -d '{
"model": "jina/jina-embeddings-v2-base-en",
"prompt": "The sky is blue because of Rayleigh scattering"
}'
Python API
ollama.embeddings(model='jina/jina-embeddings-v2-base-en', prompt='The sky is blue because of rayleigh scattering')
Javascript API
ollama.embeddings({ model: 'jina/jina-embeddings-v2-base-en', prompt: 'The sky is blue because of rayleigh scattering' })
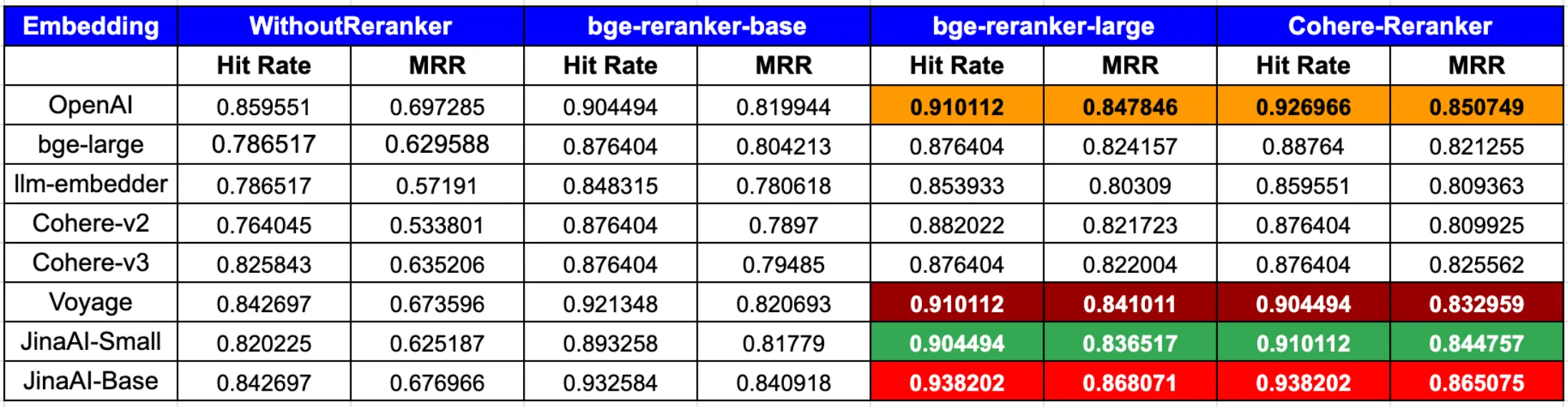
Use Jina Embeddings for RAG
According to the latest blog post from LLamaIndex,
In summary, to achieve the peak performance in both hit rate and MRR, the combination of OpenAI or JinaAI-Base embeddings with the CohereRerank/bge-reranker-large reranker stands out.