1,173 Downloads Updated 1 year ago
Llama-3-Taiwan-8B is a 8B parameter model finetuned on a large corpus of Traditional Mandarin and English data using the Llama-3 architecture. It demonstrates state-of-the-art performance on various Traditional Mandarin NLP benchmarks.
ollama run jcai/llama-3-taiwan-8b-instruct:q6_k
Details
Updated 1 year ago
1 year ago
7802e643095d · 6.6GB ·
Readme
Source:https://huggingface.co/yentinglin/Llama-3-Taiwan-8B-Instruct

🚀 Demo Site
Try out Llama-3-Taiwan interactively at twllm.com
⚔️ Chatbot Arena
Participate in the exciting Chatbot Arena and compete against other chatbots!
🚀 We’re excited to introduce Llama-3-Taiwan-70B! Llama-3-Taiwan-70B is a 70B parameter model finetuned on a large corpus of Traditional Mandarin and English data using the Llama-3 architecture. It demonstrates state-of-the-art performance on various Traditional Mandarin NLP benchmarks.
The model was trained with NVIDIA NeMo™ Framework using the NVIDIA Taipei-1 built with NVIDIA DGX H100 systems.
The compute and data for training Llama-3-Taiwan-70B was generously sponsored by Chang Gung Memorial Hospital, Chang Chun Group, Legalsign.ai, NVIDIA, Pegatron, TechOrange, and Unimicron (in alphabetical order).
We would like to acknowledge the contributions of our data provider, team members and advisors in the development of this model, including shasha77 for high-quality YouTube scripts and study materials, Taiwan AI Labs for providing local media content, Ubitus K.K. for offering gaming content, Professor Yun-Nung (Vivian) Chen for her guidance and advisement, Wei-Lin Chen for leading our pretraining data pipeline, Tzu-Han Lin for synthetic data generation, Chang-Sheng Kao for enhancing our synthetic data quality, and Kang-Chieh Chen for cleaning instruction-following data.
Model Summary
Llama-3-Taiwan-70B is a large language model finetuned for Traditional Mandarin and English users. It has strong capabilities in language understanding, generation, reasoning, and multi-turn dialogue. Key features include:
- 70B parameters
- Languages: Traditional Mandarin (zh-tw), English (en)
- Finetuned on High-quality Traditional Mandarin and English corpus covering general knowledge as well as industrial knowledge in legal, manufacturing, medical, and electronics domains
- 8K context length
- Open model released under the Llama-3 license
Training Details
- Training Framework: NVIDIA NeMo, NVIDIA NeMo Megatron
- Inference Framework: NVIDIA TensorRT-LLM
- Base model: Llama-3 70B
- Hardware: NVIDIA DGX H100 on Taipei-1
- Context length: 8K tokens (128k version)
- Batch size: 2M tokens per step
Evaluation
Checkout Open TW LLM Leaderboard for full and updated list.
| Model | TMLU | Taiwan Truthful QA | Legal Eval | TW MT-Bench | Long context | Function Calling | TMMLU+ |
|---|---|---|---|---|---|---|---|
| 學科知識 | 台灣在地化測試 | 台灣法律考題 | 中文多輪對答 | 長文本支援 | 函數呼叫 | ||
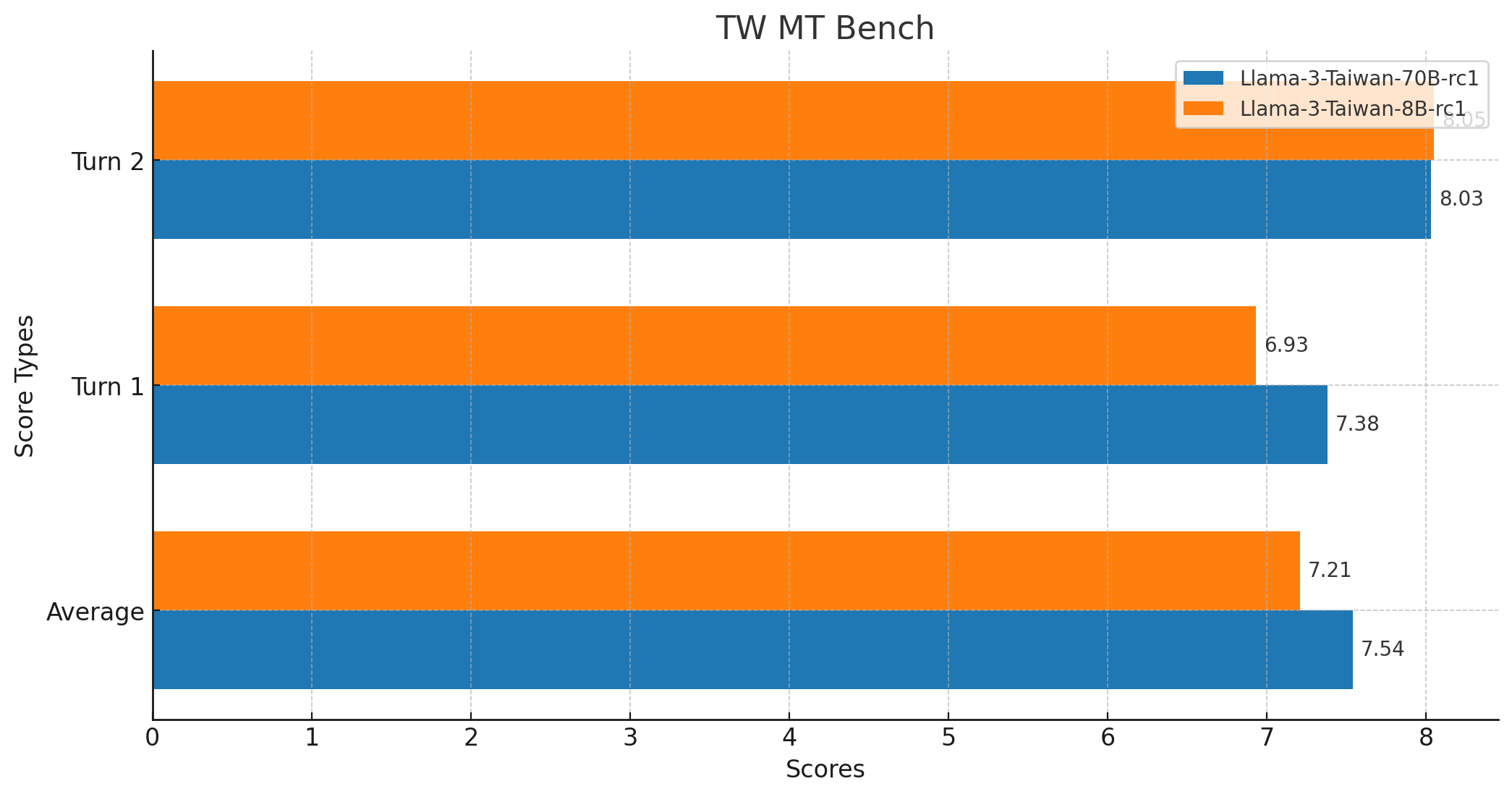
| yentinglin/Llama-3-Taiwan-70B-Instruct | 74.76% | 80.95% | 68.42% | 7.54 | 128k version | ✅ | 67.53% |
| yentinglin/Llama-3-Taiwan-70B-Instruct-DPO | 74.60% | 81.75% | 70.33% | - | - | ✅ | - |
| yentinglin/Llama-3-Taiwan-70B-Instruct-128k | 73.01% | 80.16% | 63.64% | - | - | ✅ | - |
| yentinglin/Llama-3-Taiwan-8B-Instruct | 59.50% | 61.11% | 53.11% | 7.21 | 128k version | ✅ | 52.28% |
| yentinglin/Llama-3-Taiwan-8B-Instruct-DPO | 59.88% | 59.52% | 52.63% | - | - | ✅ | - |
| yentinglin/Llama-3-Taiwan-8B-Instruct-128k | - | - | - | - | - | ✅ | - |
| Claude-3-Opus | 73.59% (5-shot) | 69.84% | 60.29% | - | 200k | ✅ | - |
| GPT4-o | 65.56% (0-shot), 69.88% (5-shot) | 76.98% | 53.59% | - | 128k | ✅ | - |
| GPT4-turbo | 70.42% (5-shot) | - | - | - | 128k | ✅ | 60.34%^ |
| Gemini-Pro | 61.40% (5-shot) | - | - | - | 1000k | ✅ | 49.92%^ |
| GPT-3.5-turbo-1106 | 49.37% (5-shot) | - | - | 7.1 | 128k | ✅ | 41.76%^ |
| Qwen1.5-110B-Chat | 75.69% | 66.67% | 49.28% | - | 32k | ✅ | 65.81% |
| Yi-34B-Chat | 73.59% | 71.43% | 55.02% | 6.9 | 200k | ✅ | 64.10% |
| Meta-Llama-3-70B-Instruct | 70.95% | 65.08% | 52.63% | - | 8k | ✅ | 62.75% |
| Mixtral-8x22B-Instruct-v0.1 | 55.57% | 52.38% | 44.98% | - | 64k | ✅ | 52.16% |
| Breexe-8x7B-Instruct-v0_1 | - | - | - | 7.2 | 8k | ❓ | 48.92% |
| c4ai-command-r-plus | 62.87% | 64.29% | 34.45% | - | 128k | ✅ | 49.75% |
| Meta-Llama-3-8B-Instruct | 55.81% | 46.83% | 35.89% | - | 8k | ✅ | 43.38% |
| Breeze-7B-Instruct-v1_0 | 55.57% | 52.38% | 39.23% | 6.0 | 32k | ❓ | 41.77% |
| Llama3-TAIDE-LX-8B-Chat-Alpha1 | 47.30% | 50.79% | 37.80% | - | 8k | ❓ | 39.03% |
| Phi-3-mini-4k-instruct | 40.97% | 37.30% | 27.27% | - | 4k | ❓ | 33.02% |
Numbers are 0-shot by default.
^ taken the closet matching numbers from original dataset.
Needle in a Haystack Evaluation
The “Needle in a 出師表” evaluation tests the model’s ability to locate and recall important information embedded within a large body of text, using the classic Chinese text 《出師表》 by 諸葛亮.
To run the evaluation, use the script.
TW MT-Bench Score
- Average Score: 7.5375
- Maximum Score: 10
- Minimum Score: 1
- Median Score: 9.0
- Standard Deviation: 3.0349783771882133
- Total Number of Scores: 160
- Model resopnse
- GPT-4 Eval
- Code fork from
mtkresearch/TCEvalwith bug fixing
Use Cases
Llama-3-Taiwan-70B can be applied to a wide variety of NLP tasks in Traditional Chinese and English, including:
1. 多輪對話
System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project. User: 嗨,你好! Assistant: 你好!我今天可以如何協助你? User: 就想聊天而已.... Assistant: 當然,我很樂意和你聊天!有什麼特別想談論的嗎?
2. RAG(檢索增強生成)
Demo: 可以打開 `Search Web` on [twllm.com](https://twllm.com/)  System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project. User: 明天台大天氣如何? Assistant: 根據天氣預報,明天台大天氣為陣雨。低溫 24°C。10 到 15 公里/小時 的 東 風 。降雨機率為 40%。
3. 格式化輸出, 語言理解, 實體識別, 函數調用
If you are interested in function-calling, I strongly recommend [using constrained decoding](https://huggingface.co/docs/text-generation-inference/basic_tutorials/using_guidance) to turn on `json mode`. Example from HW7 in `INTRODUCTION TO GENERATIVE AI 2024 SPRING` from `HUNG-YI LEE (李宏毅)` 
System: You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project.
User: 您是電影評論分析師,負責情緒分析。
分析每個被評論的句子,評估句子中每個字和標點符號的重要性,
並且將結果使用 tuple 的結構列出。
tuple 值的範圍介於 -1 (負向) 到 1 (正向) 之間,
然後,將評論分類為正向 (1) 或負向 (-1)。
這些需要被評論的句子,包含在 標籤中間。
輸出範例:
[(<單字或標點符號>, ), ...]
根據外媒報導,宏都拉斯在去年3月與台灣斷交,並轉往與中國建交之後,卻遲遲等不到中國的金援,談好要進口宏都拉斯的白蝦也拖延許久,甚至還將白蝦價格殺價至過往與台灣交易的半價,再加上墨西哥同時也中斷了與宏國的白蝦貿易,對當地蝦農可說是雪上加霜。
Assistant: [('根據', 0.2), ('外媒', 0.1), ('報導', -0.1), (',', 0.05), ('宏都拉斯', -0.3), ('在去年3月與台灣斷交, ', -0.5), ('並轉往與中國建交之後, ', -0.4), ('卻遲遲等不到中國的金援, ', -1),
('談好要進口宏都拉斯的白蝦也拖延許久, ', -1),
(',甚至還將白蝦價格殺價至過往與台灣交易的半價,再加上墨西哥同時也中斷了與宏國的白蝦貿易,對當地蝦農可說是雪上加霜。 ',-1)]
-1
Get Started
Caveat: System message should always be set.
Hugging Face Transformers library
You can use Llama-3-Taiwan-70B with the Hugging Face Transformers library:
import torch
from transformers import pipeline, StoppingCriteria
# Define a custom stopping criteria class
class EosListStoppingCriteria(StoppingCriteria):
def __init__(self, eos_sequence=[128256]):
self.eos_sequence = eos_sequence
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
last_ids = input_ids[:, -len(self.eos_sequence):].tolist()
return self.eos_sequence in last_ids
# Initialize the model with automatic device mapping
llm = pipeline("text-generation", model="yentinglin/Llama-3-Taiwan-70B-Instruct-rc1", device_map="auto")
tokenizer = llm.tokenizer
# Define a conversation example
chat = [
{"role": "system", "content": "You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project."},
{"role": "user", "content": "你好,請問你可以完成什麼任務?"},
{"role": "assistant", "content": "你好,我可以幫助您解決各種問題、提供資訊並協助完成多種任務。例如:回答技術問題、提供建議、翻譯文字、尋找資料或協助您安排行程等。請告訴我如何能幫助您。"},
{"role": "user", "content": "太棒了!"}
]
flatten_chat_for_generation = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
"""
<|im_start|>user
You are an AI assistant called Twllm, created by TAME (TAiwan Mixture of Expert) project.<|im_end|>
<|im_start|>user
你好,請問你可以完成什麼任務?<|im_end|>
<|im_start|>assistant
你好,我可以幫助您解決各種問題、提供資訊和協助您完成許多不同的任務。例如:回答技術問題、提供建議、翻譯文字、尋找資料或協助您安排行程等。請告訴我如何能幫助您。<|im_end|>
<|im_start|>user
太棒了!<|im_end|>
<|im_start|>assistant
"""
# Generate a response using the custom stopping criteria
output = llm(flatten_chat_for_generation, return_full_text=False, max_new_tokens=128, top_p=0.9, temperature=0.7, stopping_criteria=[EosListStoppingCriteria([tokenizer.eos_token_id])])
print(output[0]['generated_text'])
"謝謝!很高興能夠為您服務。如果有任何其他需要協助的地方,請隨時與我聯繫。我會盡最大努力為您提供所需的支援。"
vLLM
Start the server
export NUM_GPUS=4
export PORT=8000
docker run \
-e HF_TOKEN=$HF_TOKEN \
--gpus '"device=0,1,2,3"' \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-p "${PORT}:8000" \
--ipc=host \
vllm/vllm-openai:v0.4.0.post1 \
--model "yentinglin/Llama-3-Taiwan-70B-Instruct-rc1" \
-tp "${NUM_GPUS}"
Sample client code, or you can use anything OpenAI-API compatible clients
# pip install "openai>=1.0.0"
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="yentinglin/Llama-3-Taiwan-70B-Instruct-rc1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
print("Chat response:", chat_response)
Enjoy exploring the capabilities of Llama-3-Taiwan-70B! We look forward to seeing what you create with this powerful open-source model. If you have any questions or feedback, please let us know.
Contributions
- Professor Yun-Nung (Vivian) Chen, for her guidance and advisement throughout the project.
- Wei-Lin Chen, for leading our pretraining data pipeline.
- Tzu-Han Lin, for synthetic data generation.
- Chang-Sheng Kao, for enhancing our synthetic data quality.
- Kang-Chieh Chen, for cleaning instruction-following data.
- Min-Yi Chen and Shao-Heng Hsu, for collecting chemical engineering data and benchmarks.
- Chung-Yao Ma, Jonathan Guo and Kai-Chun Chang, for collecting manufacturing and electrical engineering data and benchmarks, and project progress management
Citation
@article{DBLP:journals/corr/abs-2311-17487,
author = {Yen{-}Ting Lin and
Yun{-}Nung Chen},
title = {Taiwan {LLM:} Bridging the Linguistic Divide with a Culturally Aligned
Language Model},
journal = {CoRR},
volume = {abs/2311.17487},
year = {2023},
url = {https://doi.org/10.48550/arXiv.2311.17487},
doi = {10.48550/ARXIV.2311.17487},
eprinttype = {arXiv},
eprint = {2311.17487},
timestamp = {Tue, 05 Dec 2023 14:40:42 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2311-17487.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@article{DBLP:journals/corr/abs-2403-20180,
author = {Po{-}Heng Chen and
Sijia Cheng and
Wei{-}Lin Chen and
Yen{-}Ting Lin and
Yun{-}Nung Chen},
title = {Measuring Taiwanese Mandarin Language Understanding},
journal = {CoRR},
volume = {abs/2403.20180},
year = {2024},
url = {https://doi.org/10.48550/arXiv.2403.20180},
doi = {10.48550/ARXIV.2403.20180},
eprinttype = {arXiv},
eprint = {2403.20180},
timestamp = {Wed, 10 Apr 2024 17:37:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2403-20180.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}