1,369 Downloads Updated 11 months ago
2-bit Q2_K_XL quantized GGUF version of Qwen3-235B-A22B-Thinking-2507 (MoE, 22B active), optimized for deep reasoning with a 262K context window. Runs on Ollama with ~86.5 GiB RAM.
ollama run frizynn/qwen3-think-235B-A22B-2507-2bit-UD-Q2_K_XL
Details
Updated 11 months ago
11 months ago
bcf0f127bdfb · 50GB ·
Readme
frizynn/qwen3-think-235B-A22B-Thinking-2507-2bit-UD-Q2_K_XL
⛓️ Library: transformers
💾 Memory requirement: ~86.5 GiB to load and run in Ollama
🛠️ Tags: qwen, qwen3, unsloth
Highlights
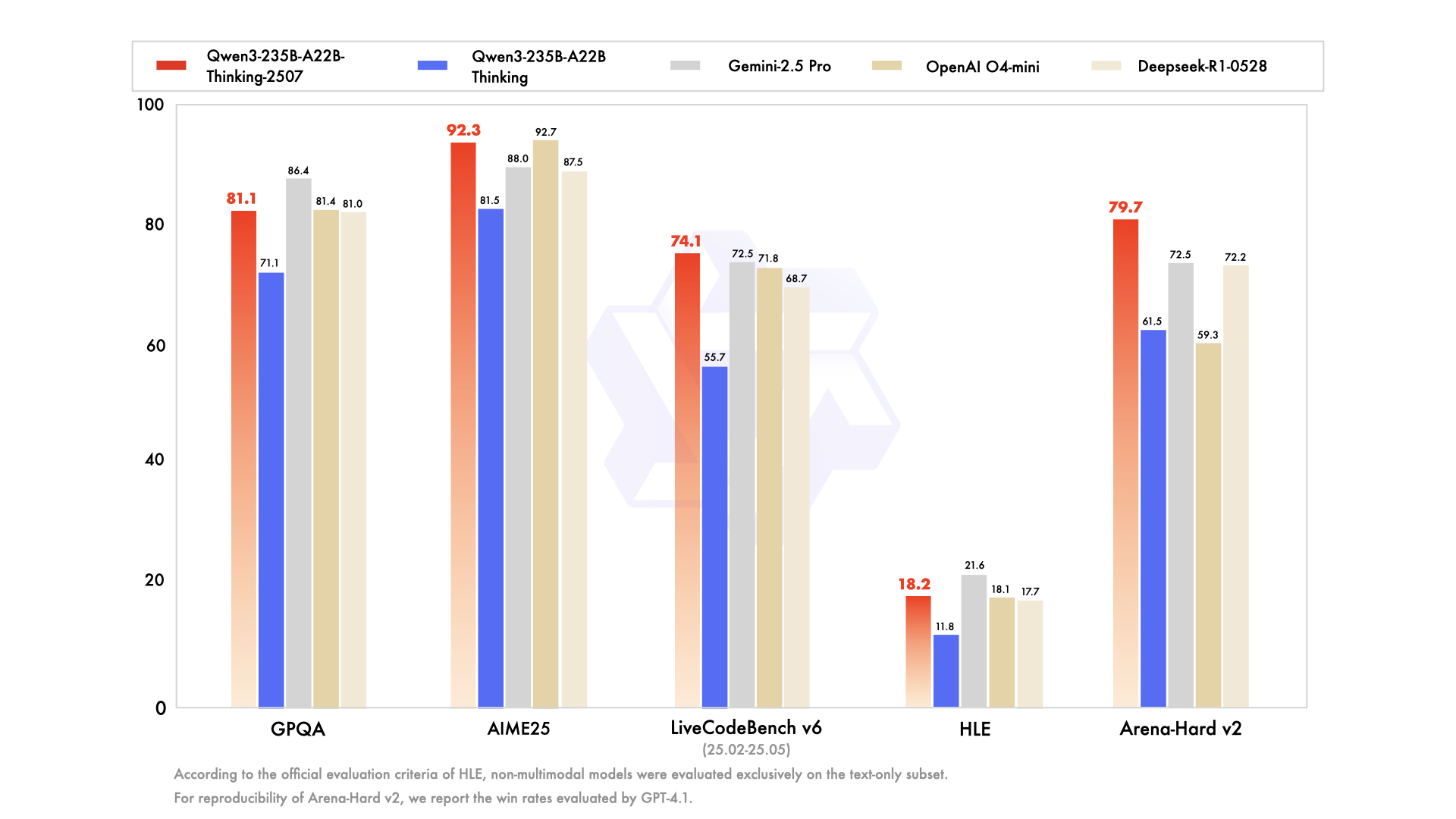
Over the past quarter, Unsloth’s Qwen3-235B-A22B-Thinking-2507 has seen major improvements in deep reasoning, instruction following, and long‑context capabilities:
- Thinking mode tuned for logic, math, coding and scientific benchmarks
- State‑of‑the‑art open‑source results on chain‑of‑thought tasks
- 256 K context window native support for very long documents
Model Overview
| Property | Details |
|---|---|
| Type | Causal Language Model |
| Parameters | 235 B total / 22 B activated (MoE experts) |
| Layers / Heads | 94 layers / 64 Q‑heads & 4 KV‑heads |
| Experts | 128 total / 8 activated per token |
| Context length | 262 144 tokens |
| Quantization | Unsloth Dynamic 2.0 → 2 bit Q2_K_XL in GGUF |
| Memory to load & run | 86.5 GiB |
Quickstart: Ollama
# Install Ollama (Linux)
curl -fsSL https://ollama.com/install.sh | sh
# Pull the model into Ollama
ollama pull frizynn/qwen3-think-235B-A22B-Thinking-2507-2bit-UD-Q2_K_XL
# Run an interactive Ollama session
ollama run frizynn/qwen3-think-235B-A22B-Thinking-2507-2bit-UD-Q2_K_XL
# ⚠️ Requires ~86.5 GiB system RAM
Example: LangChain v0.3 integration
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama.llms import OllamaLLM
# Define a simple step-by-step prompt
template = """User: {question}
Assistant (thinking):"""
prompt = ChatPromptTemplate.from_template(template)
# Point to your local Ollama model
llm = OllamaLLM(model="frizynn/qwen3-think-235B-A22B-Thinking-2507-2bit-UD-Q2_K_XL")
# Chain prompt and LLM
chain = prompt | llm
# Invoke with a question
response = chain.invoke({"question": "What are the benefits of chain‑of‑thought prompting?"})
print(response)
Memory & Performance Snapshot
| Model Alias | Memory Use |
|---|---|
| frizynn/qwen3-think-235B-A22B-Thinking-2507-2bit-UD-Q2_K_XL | 86.5 GiB |

|

|

|
Credits:
- Model by Qwen Team (Alibaba)
- Quantization via Unsloth Dynamic 2.0
- Runtime powered by Ollama
- Example integration with LangChain v0.3