4,784 Downloads Updated 2 years ago
UNOFFICIAL uploads of the DeepSeek Math 7B RL models
ollama run t1c/deepseek-math-7b-rl:Q8
Details
Updated 2 years ago
2 years ago
0d70bffb5107 · 7.3GB ·
Readme
deepseek-math-7b-rl
It’s https://huggingface.co/tastypear/deepseek-ai-deepseek-math-7b-rl-GGUF but on Ollama with a good system prompt.
Tags:
ollama run t1c/deepseek-math-7b-rl:latestQ4_K_M (default)ollama run t1c/deepseek-math-7b-rl:Q5Q5_K_Mollama run t1c/deepseek-math-7b-rl:Q6Q6_Kollama run t1c/deepseek-math-7b-rl:Q8Q8_0
Here’s a shortened version of the readme from the original GitHub repo:
![]()
Introduction
DeepSeekMath is initialized with DeepSeek-Coder-v1.5 7B and continues pre-training on math-related tokens sourced from Common Crawl, together with natural language and code data for 500B tokens. DeepSeekMath 7B has achieved an impressive score of 51.7% on the competition-level MATH benchmark without relying on external toolkits and voting techniques, approaching the performance level of Gemini-Ultra and GPT-4. For research purposes, we release checkpoints of base, instruct, and RL models to the public.
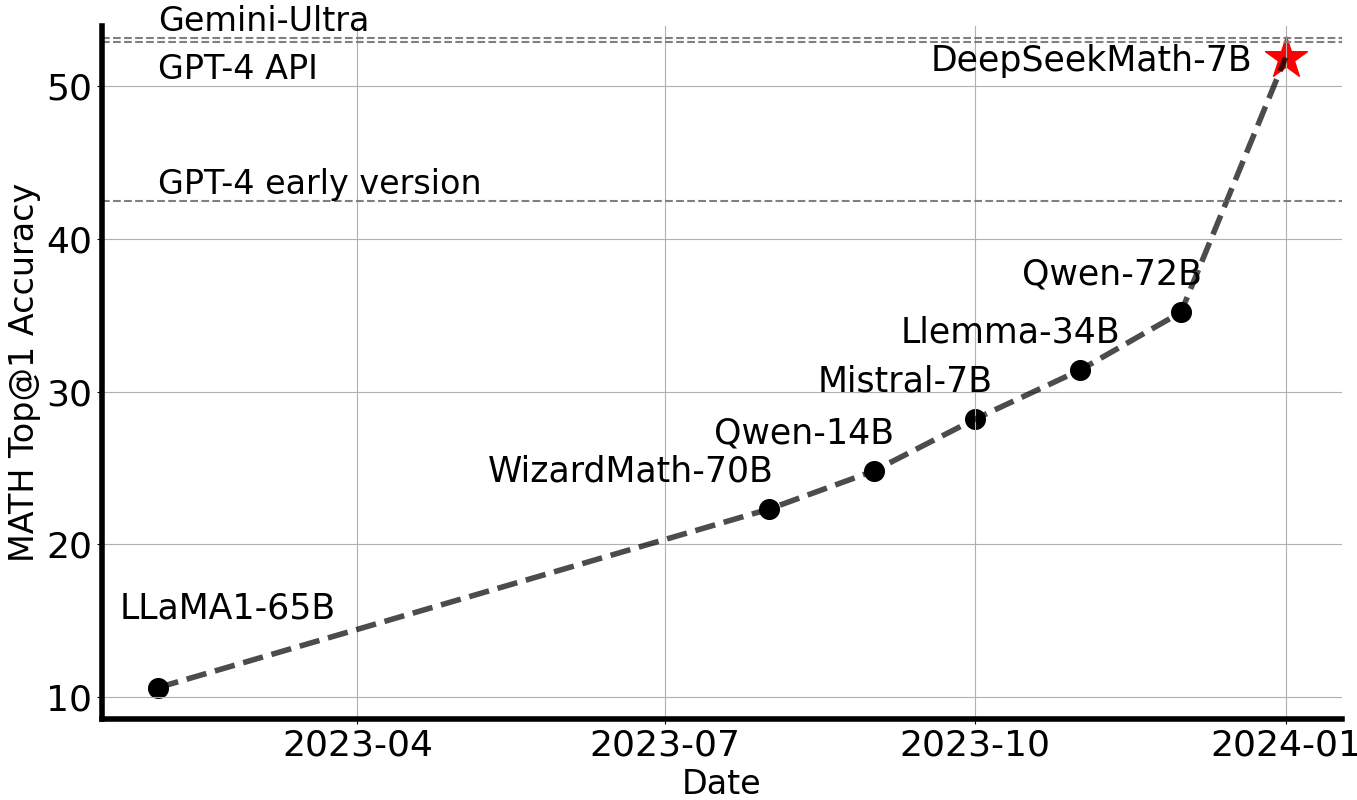
Evaluation Results
DeepSeekMath-Base 7B
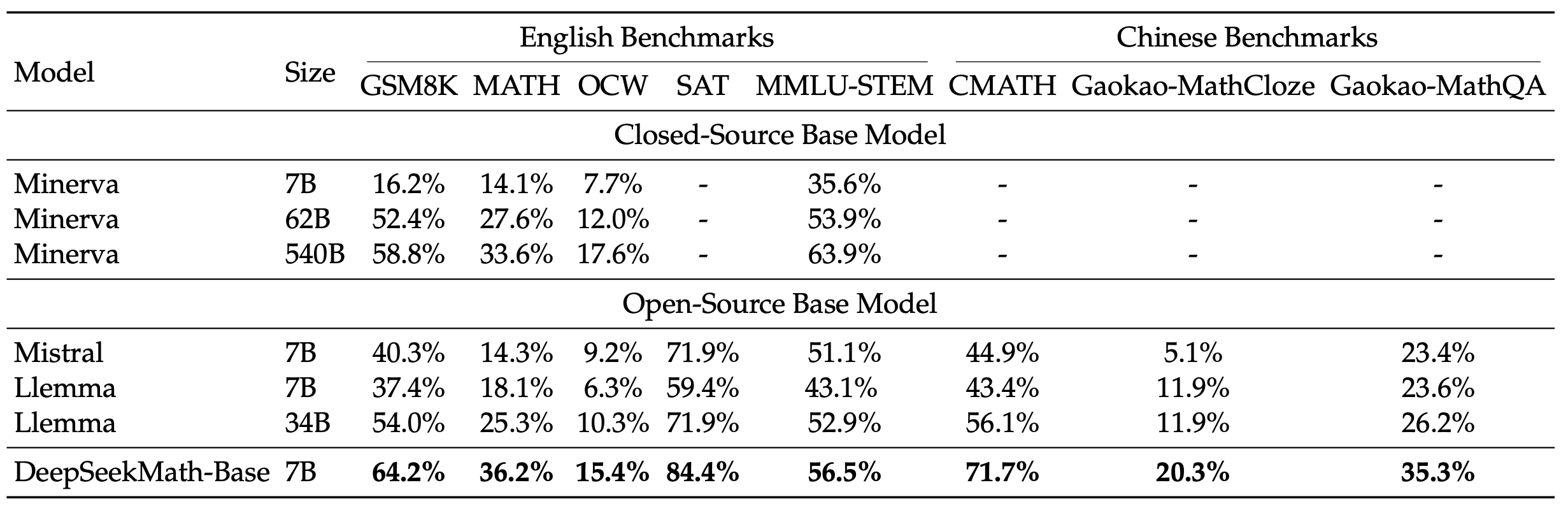
We conduct a comprehensive assessment of the mathematical capabilities of DeepSeekMath-Base 7B, focusing on its ability to produce self-contained mathematical solutions without relying on external tools, solve math problems using tools, and conduct formal theorem proving. Beyond mathematics, we also provide a more general profile of the base model, including its performance of natural language understanding, reasoning, and programming skills.
- Mathematical problem solving with step-by-step reasoning
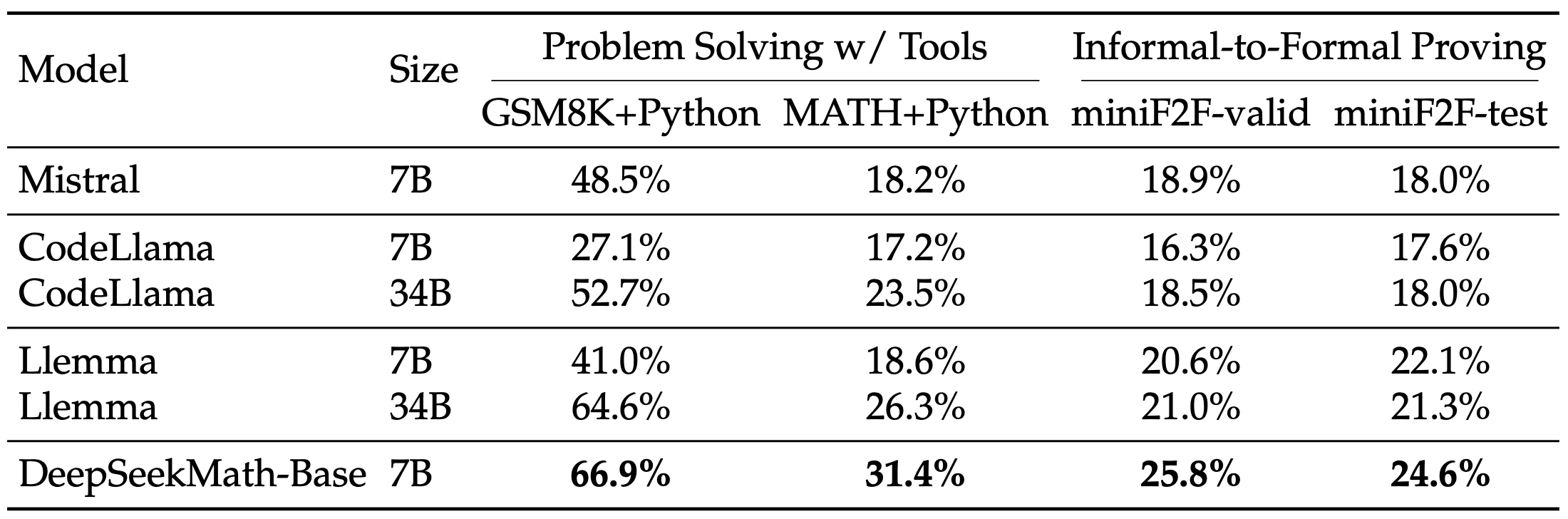
- Mathematical problem solving with tool use
- Natural Language Understanding, Reasoning, and Code
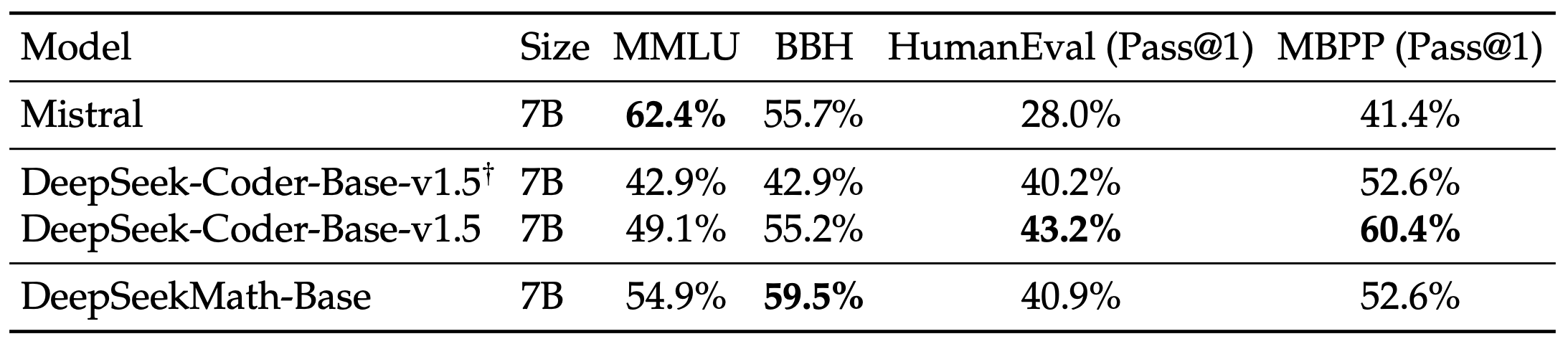
The evaluation results from the tables above can be summarized as follows: - Superior Mathematical Reasoning: On the competition-level MATH dataset, DeepSeekMath-Base 7B outperforms existing open-source base models by more than 10% in absolute terms through few-shot chain-of-thought prompting, and also surpasses Minerva 540B. - Strong Tool Use Ability: Continuing pre-training with DeepSeekCoder-Base-7B-v1.5 enables DeepSeekMath-Base 7B to more effectively solve and prove mathematical problems by writing programs. - Comparable Reasoning and Coding Performance: DeepSeekMath-Base 7B achieves performance in reasoning and coding that is comparable to that of DeepSeekCoder-Base-7B-v1.5.
DeepSeekMath-Instruct and -RL 7B
DeepSeekMath-Instruct 7B is a mathematically instructed tuning model derived from DeepSeekMath-Base 7B, while DeepSeekMath-RL 7B is trained on the foundation of DeepSeekMath-Instruct 7B, utilizing our proposed Group Relative Policy Optimization (GRPO) algorithm.
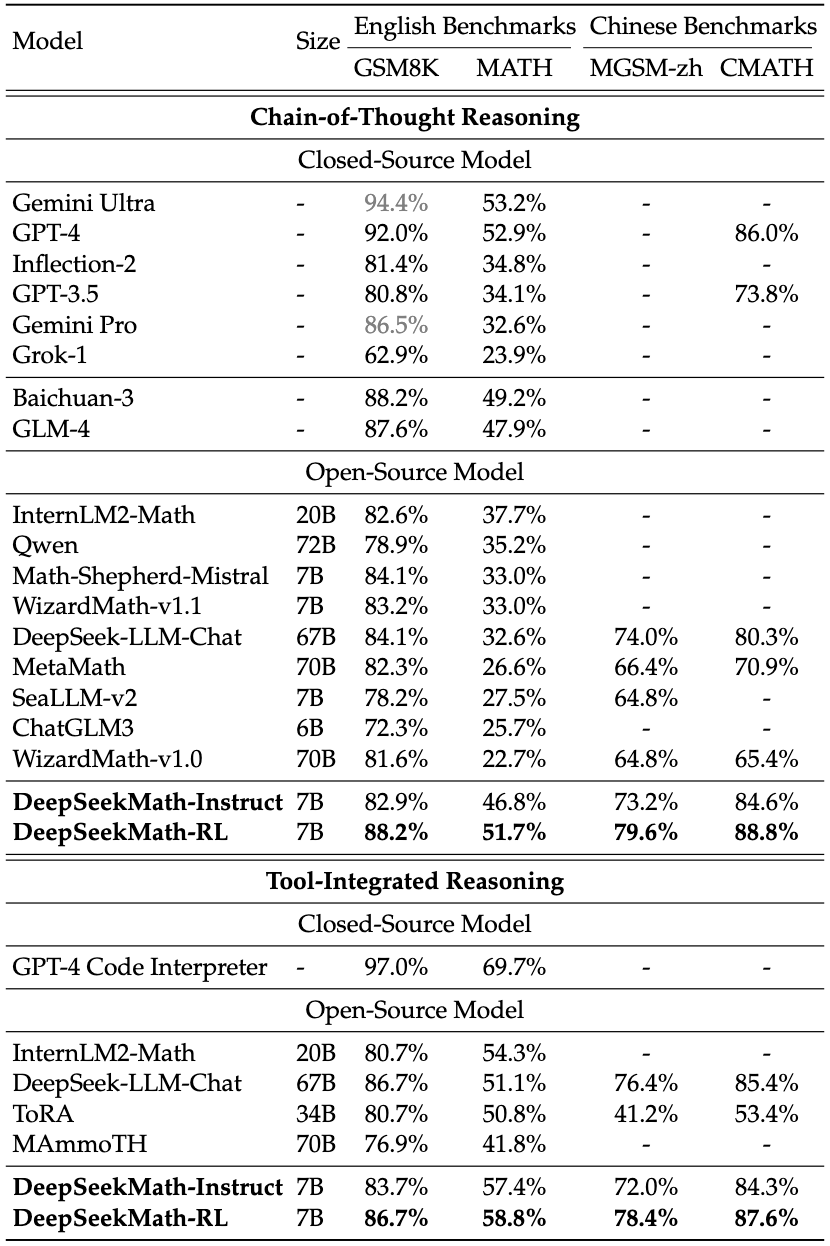
We evaluate mathematical performance both without and with tool use, on 4 quantitative reasoning benchmarks in English and Chinese. As shown in Table, DeepSeekMath-Instruct 7B demonstrates strong performance of step-by-step reasoning, and DeepSeekMath-RL 7B approaches an accuracy of 60% on MATH with tool use, surpassing all existing open-source models.
Data Collection
- Step 1: Select OpenWebMath, a collection of high-quality mathematical web texts, as our initial seed corpus for training a FastText model.
- Step 2: Use the FastText model to retrieve mathematical web pages from the deduplicated Common Crawl database.
- Step 3: Identify potential math-related domains through statistical analysis.
- Step 4: Manually annotate URLs within these identified domains that are associated with mathematical content.
- Step 5: Add web pages linked to these annotated URLs, but not yet collected, to the seed corpus. Jump to step 1 until four iterations.
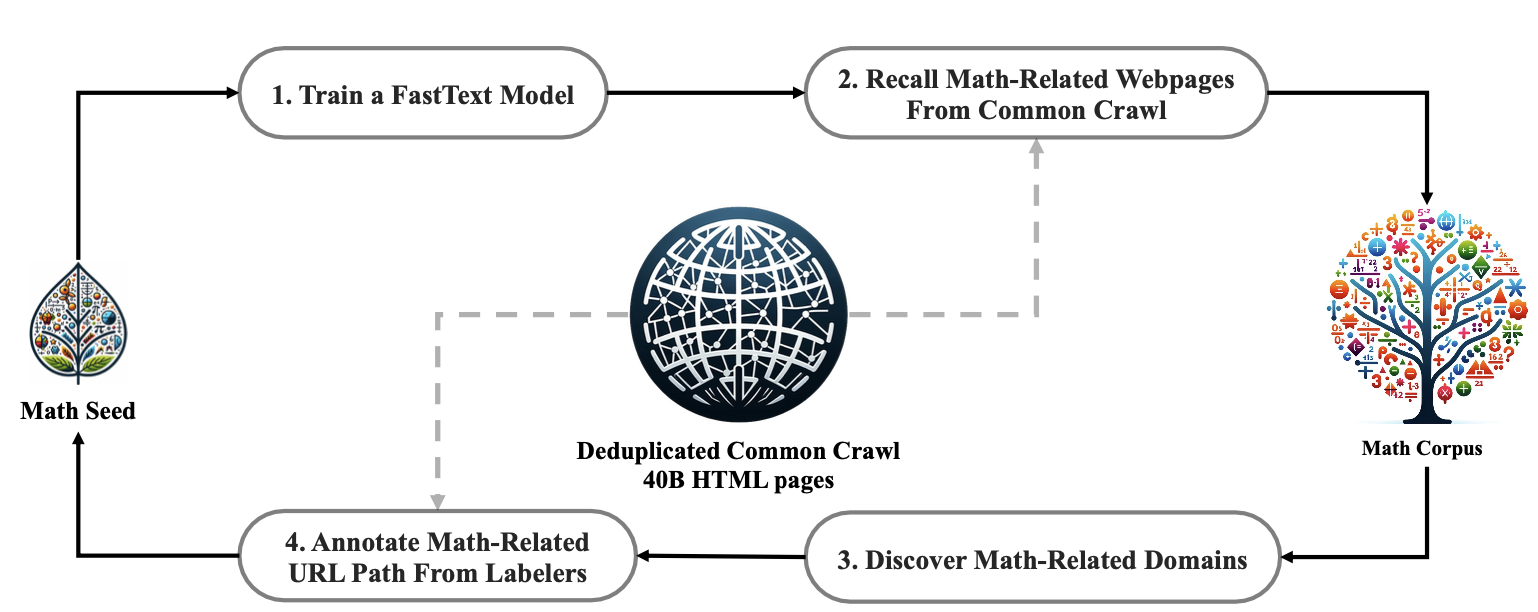
After four iterations of data collection, we end up with 35.5M mathematical web pages, totaling 120B tokens.
Citation
@misc{deepseek-math,
author = {Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y.K. Li, Y. Wu, Daya Guo},
title = {DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models},
journal = {CoRR},
volume = {abs/2402.03300},
year = {2024},
url = {https://arxiv.org/abs/2402.03300},
}
Contact
If you have any questions, please raise an issue or contact DeepSeek at service@deepseek.com.