593 Downloads Updated 2 years ago
A strong, economical, and efficient Mixture-of-Experts language model.
ollama run mannix/deepseek-v2-lite-instruct:q3_k_m
Details
Updated 2 years ago
2 years ago
f9c0fb3c583d · 8.1GB ·
Readme
- Quantization from
fp32 - Using i-matrix
calibration_datav3.txt - New template:
- should work with
flash_attention - doesn’t forget the
SYSTEMprompt - doesn’t forget the context
- should work with
- N.B: if the output breaks ask for
repeat(but it shouldn’t with these quants)
DeepSeek-V2 is a a strong Mixture-of-Experts (MoE) language model characterized by economical training and efficient inference.
Note: this model is bilingual in English and Chinese.

Introduction
Last week, the release and buzz around DeepSeek-V2 have ignited widespread interest in MLA (Multi-head Latent Attention)! Many in the community suggested open-sourcing a smaller MoE model for in-depth research. And now DeepSeek-V2-Lite comes out:
- 16B total params, 2.4B active params, scratch training with 5.7T tokens
- Outperforms 7B dense and 16B MoE on many English & Chinese benchmarks
- Deployable on single 40G GPU, fine-tunable on 8x80G GPUs
DeepSeek-V2, a strong Mixture-of-Experts (MoE) language model characterized by economical training and efficient inference. DeepSeek-V2 adopts innovative architectures including Multi-head Latent Attention (MLA) and DeepSeekMoE. MLA guarantees efficient inference through significantly compressing the Key-Value (KV) cache into a latent vector, while DeepSeekMoE enables training strong models at an economical cost through sparse computation.
Model Architecture
DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference: - For attention, we design MLA (Multi-head Latent Attention), which utilizes low-rank key-value union compression to eliminate the bottleneck of inference-time key-value cache, thus supporting efficient inference. - For Feed-Forward Networks (FFNs), we adopt DeepSeekMoE architecture, a high-performance MoE architecture that enables training stronger models at lower costs.
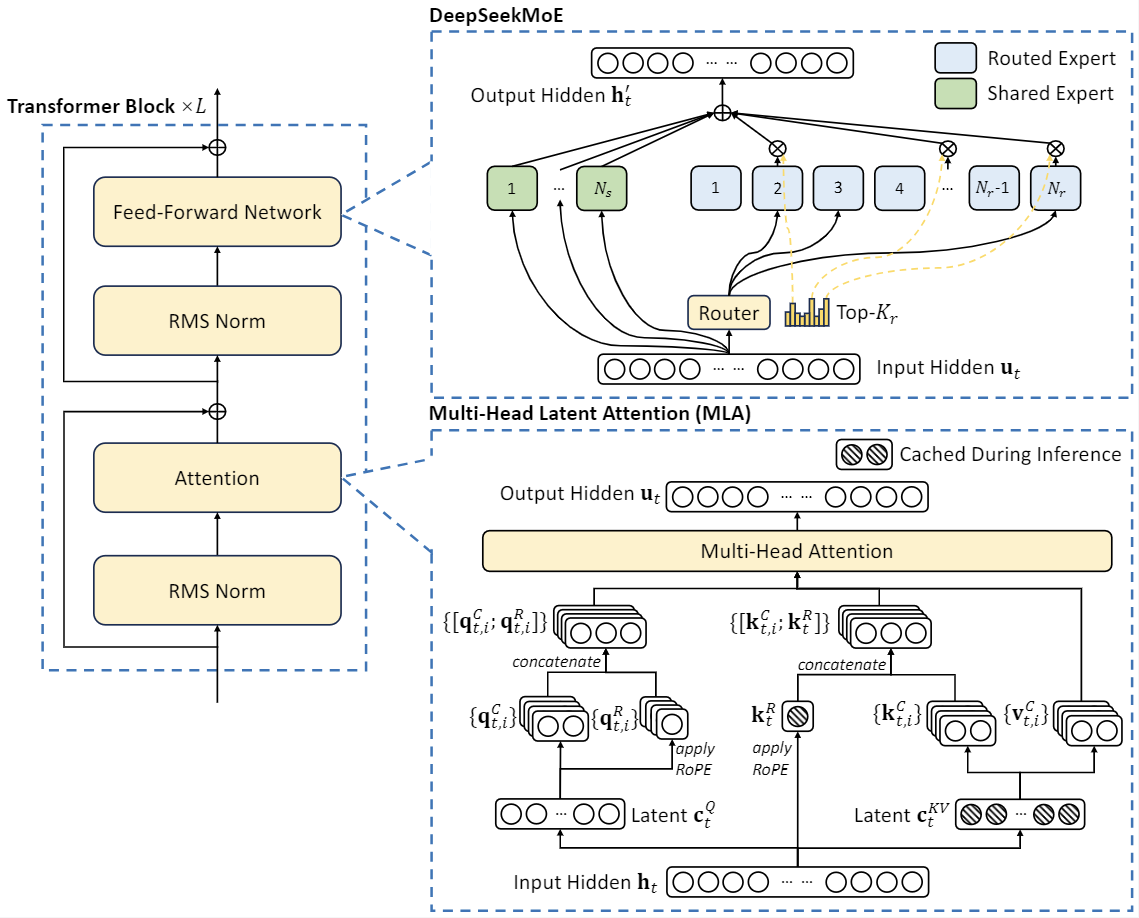
DeepSeek-V2-Lite has 27 layers and a hidden dimension of 2048. It also employs MLA and has 16 attention heads, where each head has a dimension of 128. Its KV compression dimension is 512, but slightly different from DeepSeek-V2, it does not compress the queries. For the decoupled queries and key, it has a per-head dimension of 64. DeepSeek-V2-Lite also employs DeepSeekMoE, and all FFNs except for the first layer are replaced with MoE layers. Each MoE layer consists of 2 shared experts and 64 routed experts, where the intermediate hidden dimension of each expert is 1408. Among the routed experts, 6 experts will be activated for each token. Under this configuration, DeepSeek-V2-Lite comprises 15.7B total parameters, of which 2.4B are activated for each token.
Training Details
DeepSeek-V2-Lite is also trained from scratch on the same pre-training corpus of DeepSeek-V2, which is not polluted by any SFT data. It uses the AdamW optimizer with hyper-parameters set to \(\beta_1=0.9\), \(\beta_2=0.95\), and \(\mathrm{weight_decay}=0.1\). The learning rate is scheduled using a warmup-and-step-decay strategy. Initially, the learning rate linearly increases from 0 to the maximum value during the first 2K steps. Subsequently, the learning rate is multiplied by 0.316 after training about 80% of tokens, and again by 0.316 after training about 90% of tokens. The maximum learning rate is set to \(4.2 \times 10^{-4}\), and the gradient clipping norm is set to 1.0. We do not employ the batch size scheduling strategy for it, and it is trained with a constant batch size of 4608 sequences. During pre-training, we set the maximum sequence length to 4K, and train DeepSeek-V2-Lite on 5.7T tokens. We leverage pipeline parallelism to deploy different layers of it on different devices, but for each layer, all experts will be deployed on the same device. Therefore, we only employ a small expert-level balance loss with \(\alpha_{1}=0.001\), and do not employ device-level balance loss and communication balance loss for it. After pre-training, we also perform long-context extension, SFT for DeepSeek-V2-Lite and get a chat model called DeepSeek-V2-Lite Chat.