Llama 3.2 Vision
November 6, 2024
Llama 3.2 Vision is now available to run in Ollama, in both 11B and 90B sizes.
Get started
Download Ollama 0.4, then run:
ollama run llama3.2-vision
To run the larger 90B model:
ollama run llama3.2-vision:90b
To add an image to the prompt, drag and drop it into the terminal, or add a path to the image to the prompt on Linux.
Note: Llama 3.2 Vision 11B requires least 8GB of VRAM, and the 90B model requires at least 64 GB of VRAM.
Examples
Handwriting
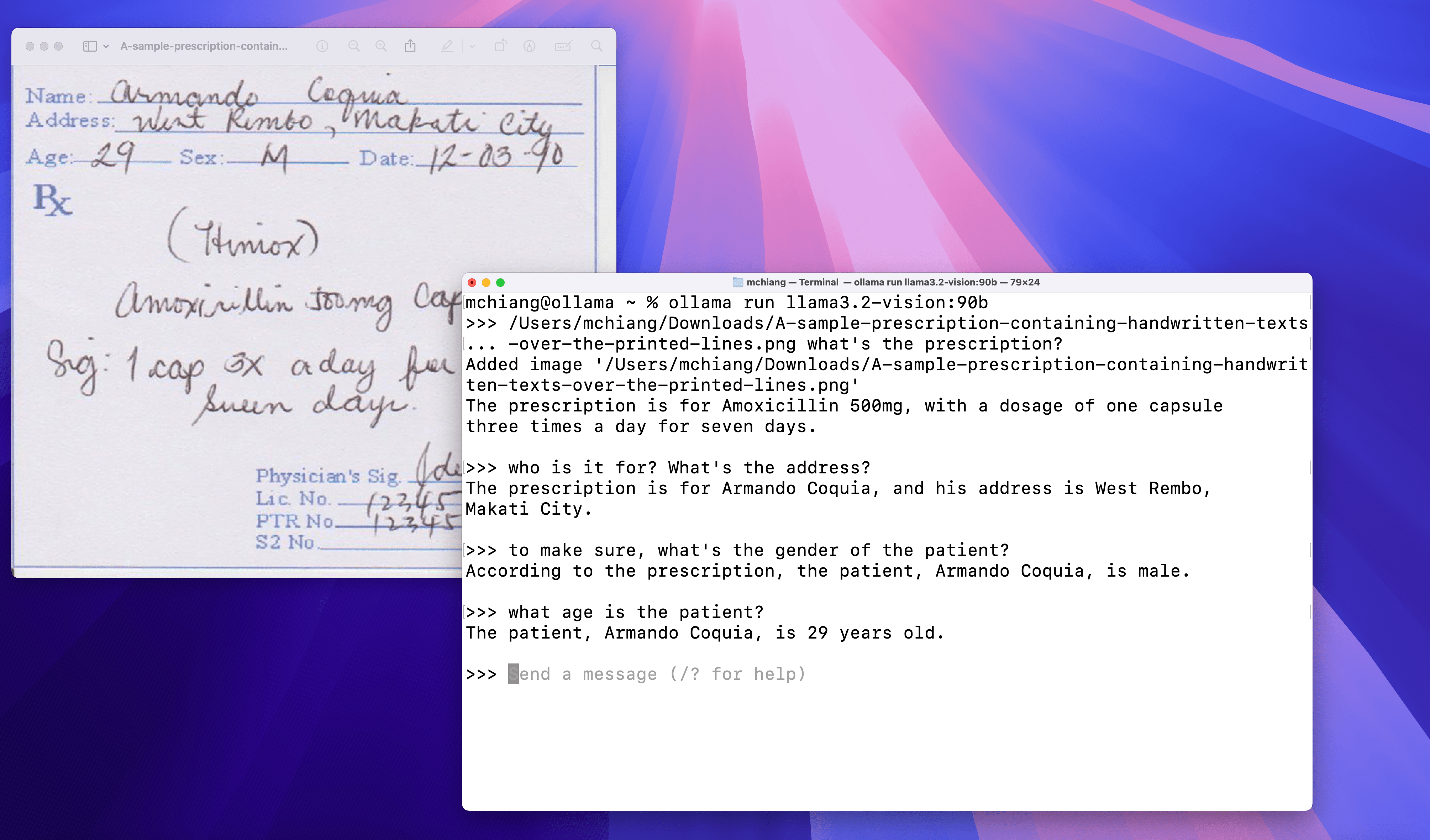
Optical Character Recognition (OCR)

Charts & tables
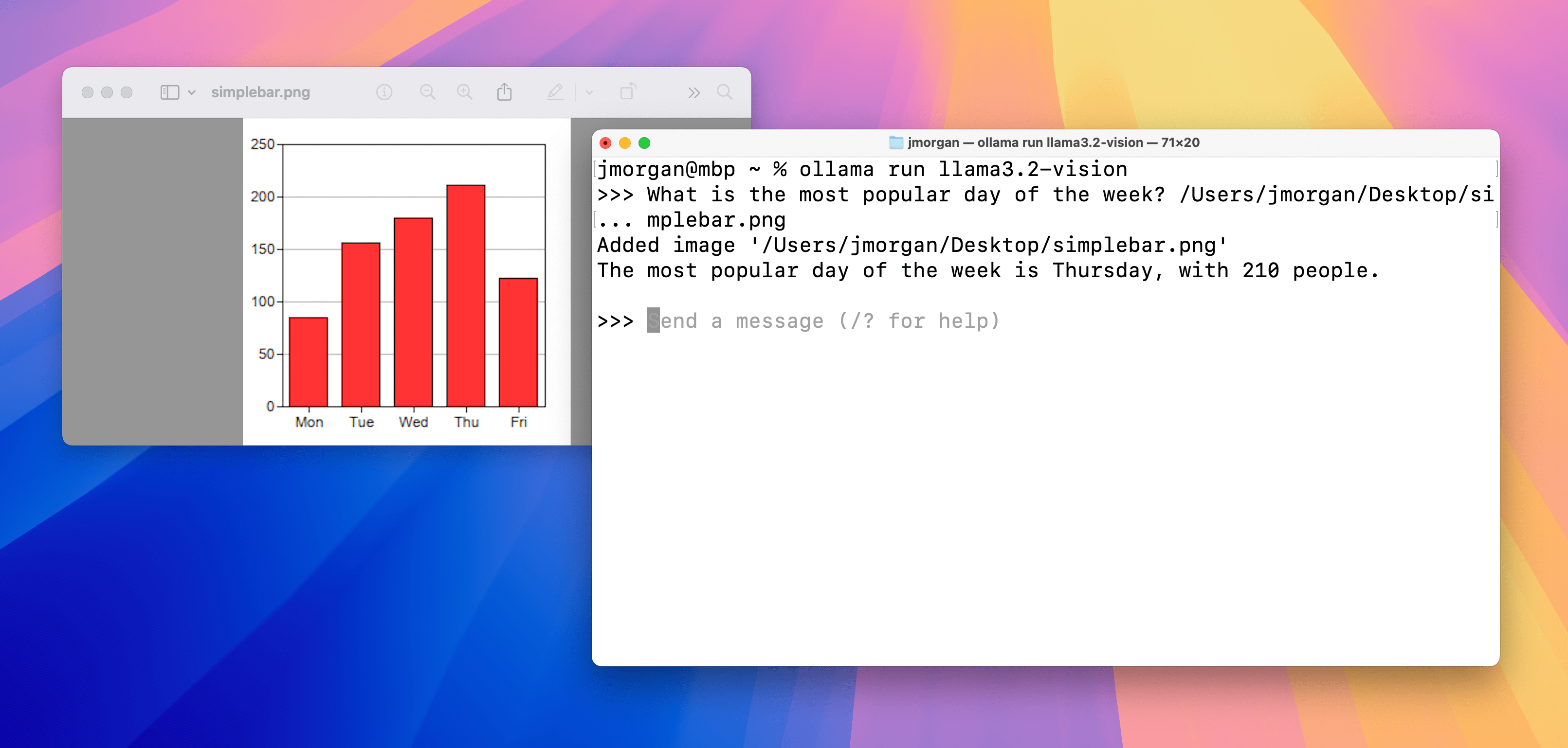
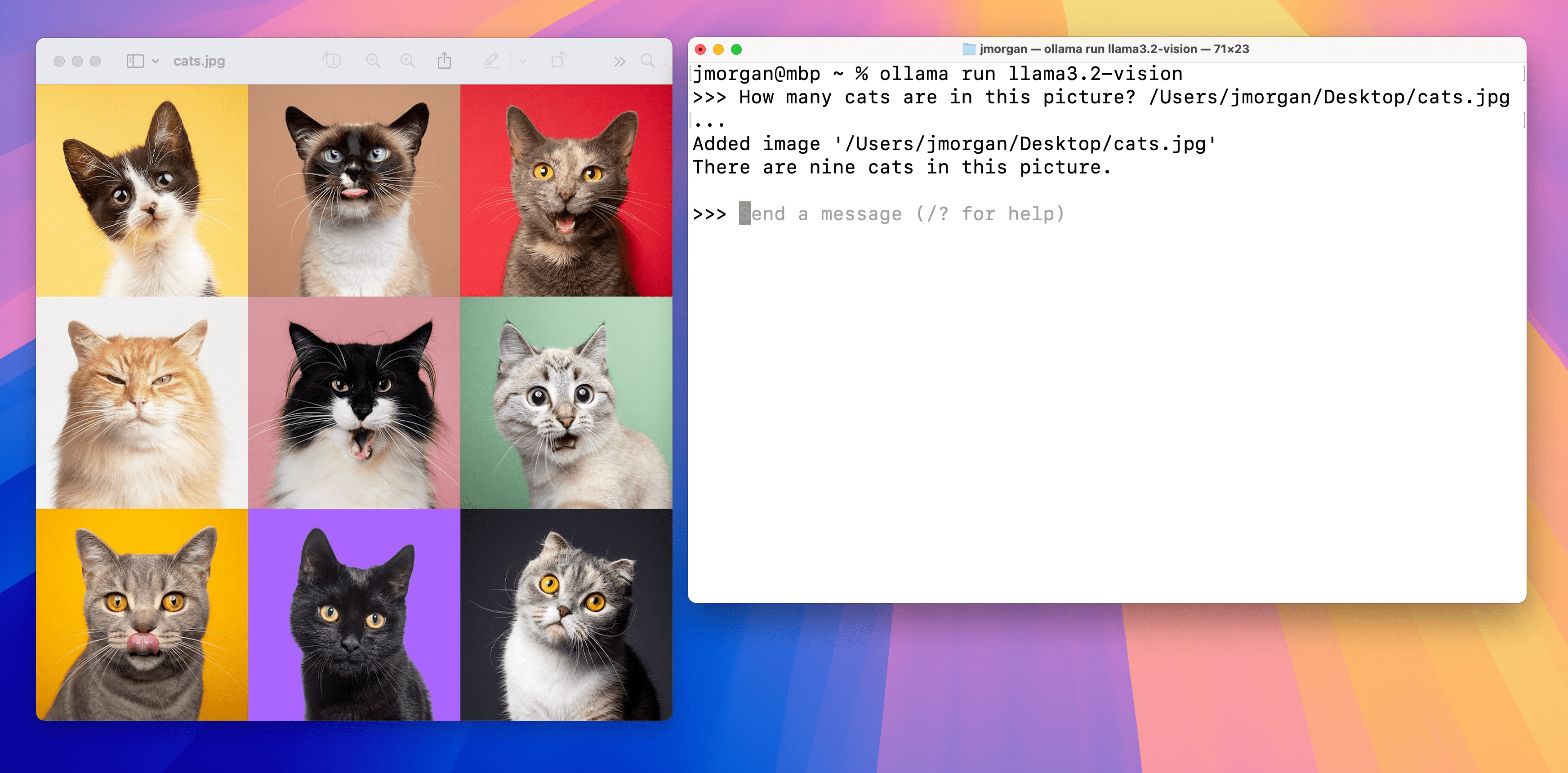
Image Q&A
Usage
First, pull the model:
ollama pull llama3.2-vision
Python Library
To use Llama 3.2 Vision with the Ollama Python library:
import ollama
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': 'What is in this image?',
'images': ['image.jpg']
}]
)
print(response)
JavaScript Library
To use Llama 3.2 Vision with the Ollama JavaScript library:
import ollama from 'ollama'
const response = await ollama.chat({
model: 'llama3.2-vision',
messages: [{
role: 'user',
content: 'What is in this image?',
images: ['image.jpg']
}]
})
console.log(response)
cURL
curl http://localhost:11434/api/chat -d '{
"model": "llama3.2-vision",
"messages": [
{
"role": "user",
"content": "what is in this image?",
"images": ["<base64-encoded image data>"]
}
]
}'
