1,028 Downloads Updated 11 months ago
This repo contains both the Q4_K_XL version of Qwen3-30B-A3B-Instruct-2507 and Qwen3-30B-A3B-Thinking-2507
ollama run SimonPu/qwen3:30B-Thinking-2507-Q4_K_XL
Details
Updated 11 months ago
11 months ago
cf3d85b604d6 · 18GB ·
Readme
Qwen3-30B-A3B-Instruct-2507 and Qwen3-30B-A3B-Thinking-2507
Highlights
We introduce the updated version of the Qwen3-30B-A3B mode, named Qwen3-30B-A3B-Instruct-2507 and Qwen3-30B-A3B-Thinking-2507, featuring the following key enhancements:
- Significant improvements in general capabilities, including instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage.
- Substantial gains in long-tail knowledge coverage across multiple languages.
- Markedly better alignment with user preferences in subjective and open-ended tasks, enabling more helpful responses and higher-quality text generation.
- Enhanced capabilities in 256K long-context understanding.
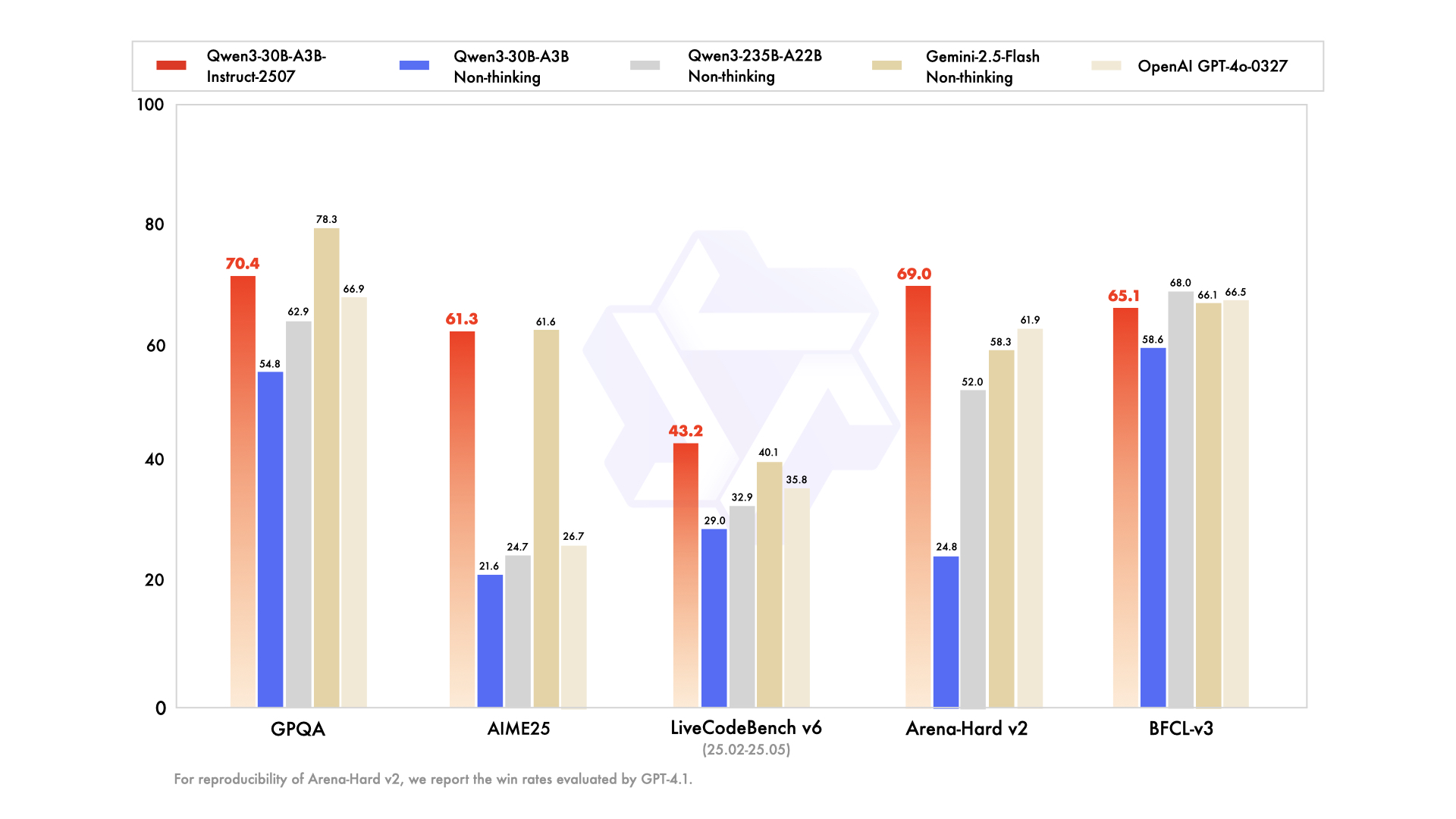
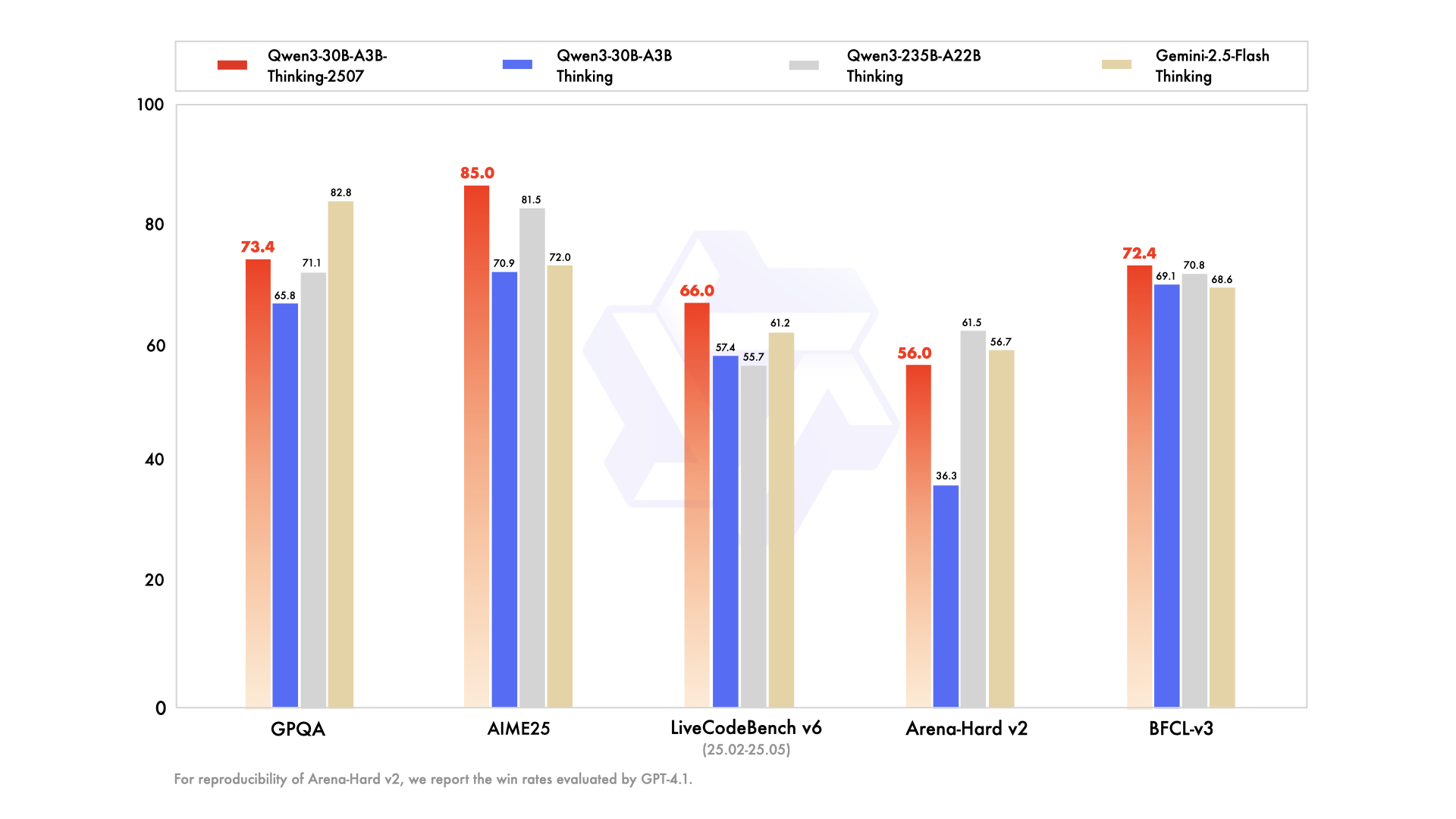
Model Overview
This repo contains both the Q4_K_XL version of Qwen3-30B-A3B-Instruct-2507 and Qwen3-30B-A3B-Thinking-2507, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: 262,144 natively.
NOTE: This model supports only non-thinking mode and does not generate <think></think> blocks in its output. Meanwhile, specifying enable_thinking=False is no longer required.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our blog, GitHub, and Documentation.
Best Practices
To achieve optimal performance, we recommend the following settings:
Sampling Parameters:
- We suggest using
Temperature=0.7,TopP=0.8,TopK=20, andMinP=0for Instruct model andTemperature=0.6,TopP=0.95,TopK=20, andMinP=0for Thinking Model . - For supported frameworks, you can adjust the
presence_penaltyparameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
- We suggest using
Adequate Output Length: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
Standardize Output Format: We recommend using prompts to standardize model outputs when benchmarking.
- Math Problems: Include “Please reason step by step, and put your final answer within \boxed{}.” in the prompt.
- Multiple-Choice Questions: Add the following JSON structure to the prompt to standardize responses: “Please show your choice in the
answerfield with only the choice letter, e.g.,"answer": "C".”
Citation
If you find our work helpful, feel free to give us a cite.
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}